Advance Time Series Researcher 소개
Time Series Researcher 애플리케이션은 많은 무작위 변수 샘플(시계열)을 저장(편집, 삭제, 이름 변경)하도록 설계되었습니다. 무작위 변수 샘플의 경우 기본 통계 특성을 다음과 같이 계산하고 저장합니다. - 샘플 크기 최소 및 최대 값; - 표본의 산술 평균; - 샘플 모드; - 표본의 중앙값; - 표본의 하위 사분위수 - 표본의 상위 사분위수 - 샘플의 낮은 십분위; - 표본의 상위 10분위수 - 샘플의 평균 절대 편차; - 표본의 표준편차 - 편향된(보정되지 않은) 추정량; - 표본 표준편차 - 편향되지 않은(보정된) 추정량; - 표본 분산 - 편향된(수정되지 않은) 추정기; - 표본 분산 - 편향되지 않은(보정된) 추정량; - 표본의 계수 분산; - 표본의 분산 범위 - 표본의 사분위수 범위; - 표본의 십분위수 범위; - 샘플의 사분위 편차; - 샘플의 십분위 편차; - 표본 왜도; - 표본 첨도; - 영점 왜도가 거부되었는지 또는 거부되지 않았는지 확인합니다(소표본). - 0첨도가 거부되었는지 또는 거부되지 않았는지 확인합니다(소표본). - 정규분포가 기각되거나 기각되지 않음(소표본) - m-test를 확인하세요: 왜도 0이 거부되거나 거부되지 않음(큰 표본의 경우); - m-test 확인: 첨도 0이 거부되거나 거부되지 않음(큰 표본의 경우) - m-test 확인: 정규 분포가 거부되거나 거부되지 않음(큰 표본의 경우).
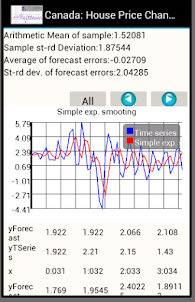
앞서 언급한 기본 통계 특성의 계산과 함께 응용 프로그램은 Pearson 기준에 따라 정규 및 균일 분포를 확인하고, 주어진 확률을 가진 모집단의 비율이 해당되도록 한계를 계산합니다. 이 애플리케이션에는 시계열 유형 샘플의 자기상관 및 5가지 유형 예측을 계산하는 기능이 있습니다. 이 응용 프로그램에는 위에서 언급한 통계적 특성을 계산하기 위한 공식이 있습니다.
샘플, 처리 특성 결과, 자기 상관 및 시계열 예측을 데이터베이스(Sqlit)에 저장할 수 있습니다. 이러한 데이터가 포함된 테이블은 예를 들어 Sqlit 브라우저를 사용하거나 Interne을 통해 전송하여 인쇄하기 위해 내보낼 수 있습니다. 따라서 데이터베이스를 다른 미디어에 저장할 수 있습니다. 응용 프로그램을 부팅하면 시작 활동 메뉴에서 "init DB"(initiate DB)를 실행합니다. 이 기능을 구현하면 제안된 샘플이 청구됩니다.
앞서 언급한 기본 통계 특성의 계산과 함께 응용 프로그램은 Pearson 기준에 따라 정규 및 균일 분포를 확인하고, 주어진 확률을 가진 모집단의 비율이 해당되도록 한계를 계산합니다. 이 애플리케이션에는 시계열 유형 샘플의 자기상관 및 5가지 유형 예측을 계산하는 기능이 있습니다. 이 응용 프로그램에는 위에서 언급한 통계적 특성을 계산하기 위한 공식이 있습니다.
샘플, 처리 특성 결과, 자기 상관 및 시계열 예측을 데이터베이스(Sqlit)에 저장할 수 있습니다. 이러한 데이터가 포함된 테이블은 예를 들어 Sqlit 브라우저를 사용하거나 Interne을 통해 전송하여 인쇄하기 위해 내보낼 수 있습니다. 따라서 데이터베이스를 다른 미디어에 저장할 수 있습니다. 응용 프로그램을 부팅하면 시작 활동 메뉴에서 "init DB"(initiate DB)를 실행합니다. 이 기능을 구현하면 제안된 샘플이 청구됩니다.
더 보기